A propósito de la situación actual en California, decidimos mapear la población latina en ese estado. Aquí está cómo lo hicimos con R.
Cargar datos censales
Usamos datos del censo, descargados con tidycensus. La llave para el API la conseguimos acá.
library(tidycensus)
library(tidyverse)
census_api_key("TU_LLAVE", install = TRUE)
# Cargamos los datos censales
eth_data <-
get_acs(
geography = "tract", # nivel censal: tract
state = "CA",
variables = c(hispanic = "B03003_003", # code de pop. hispana
total = "B03003_001" # code de pop. total
),
year = 2022,
geometry = TRUE
)
# calculamos el porcentaje de pob.
eth_pct <-
eth_data |>
select(GEOID, variable, estimate, geometry) |>
pivot_wider(names_from = variable, values_from = estimate) |>
mutate(
hispanic = replace_na(hispanic, 0),
pct_hispanic = 100 * hispanic / total
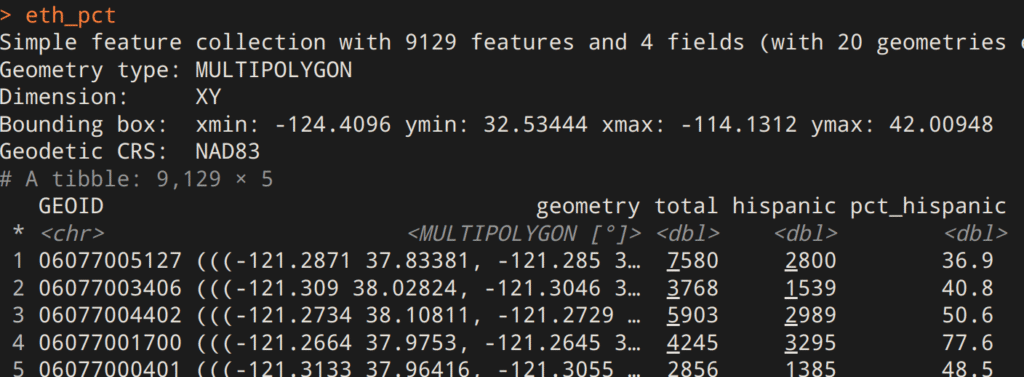
)El resultado es un objeto sf con las geometrías de tractos del censo, y la población calculada para cada tracto de California. Ahora, podemos usarlo para mapear.
Mapas 2D y 3D
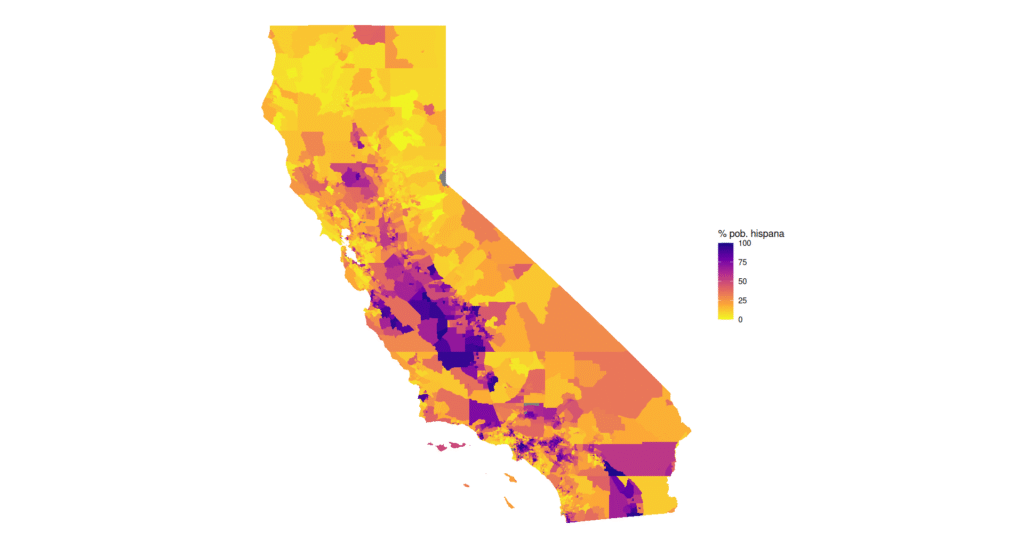
Para visualizar este objeto, podemos hacerlo simplemente con ggplot. Algo así:
p <-
ggplot(eth_pct) +
geom_sf(aes(fill = pct_hispanic), color = NA) +
scale_fill_viridis_c("% pob. hispana", option = "plasma", direction = -1) +
theme_void()Y con eso tenemos un mapa de calor de la población latina en California. Se vería algo así:
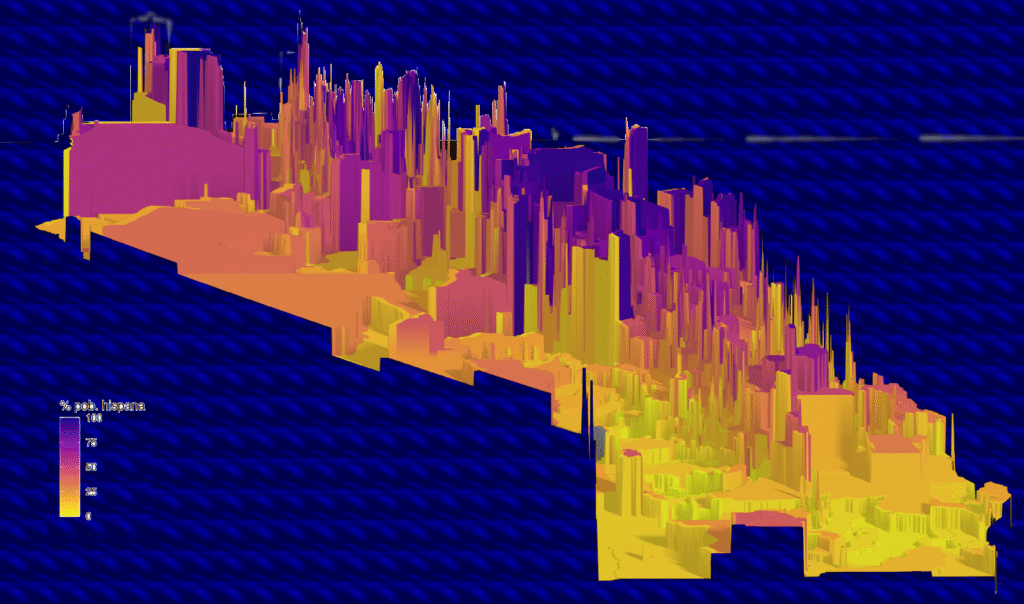
Y ahora… si queremos tener este mapa en 3D, podemos hacerlo utilizando rayshader.
rayshader::plot_gg(
p,
multicore = TRUE,
width = 6,
height = 6,
scale = 250,
zoom = 0.75,
phi = 30,
theta = 135
)
Y con eso podemos tener una visualización de impacto para ubicar fácilmente los lugares con mayor porcentaje de población latina en California
Una oportunidad más para usar datos y con ellos contribuir a las conversaciones de interés. Porque las discusiones pueden ser más productivas con datos.